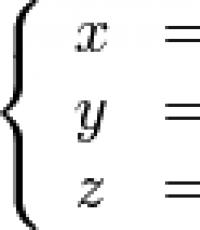Формальные языки и грамматики. Описание формальных грамматик Теория формальных грамматик
При создании формальных языков необходимо выбрать множество базовых знаков для формирования лексем, указать множество синтаксических правил написания выражений и предложений, согласовать множество семантических правил для интерпретации их значений. Подобно естественным языкам, грамматики формальных языков организованы в виде иерархии синтаксических конструкций, формирующих лексемы и последовательности лексем - выражения и предложения. Элементы нижнего уровня образованы знаками базового набора и формируют слова или лексемы формального языка. Элементы следующих уровней, образованные цепочками лексем и/или синтаксических переменных, формируют выражения формального языка. Элементы самого верхнего уровня, образованные цепочками выражений, формируют предложение. Так как языки программирования являются формальными языками, то все последующие обсуждения будем сопровождать примерами на этих языках.
Множество базовых знаков, используемых в языках программирования, опирается на 26 строчных и прописных букв латинского алфавита, на 10 арабских цифр и на 26 специальных символов, имеющих фиксированное значение (знаки препинания, арифметических действий, сравнения и т.п.).
Множество синтаксических правил, по которым строят синтаксически правильные выражения и предложения программы, определяет содержание грамматики языка программирования.
Для формирования модели грамматики обозначим элементарные лексические единицы языка строчными буквами латинского алфавита. Знаки этого множества называют терминальными (от лат. terminus - предел,конец). Множество терминальных символов обозначим знаком V T . Это множество называют также словарем или лексикой языка. Множество V T - счетно, но не конечно, т.к. всегда можно добавить новую лексему для какой-либо синтаксической переменной.
Элементарными лексическими единицами большинства языков программирования являются:
значения идентификаторов констант, переменных, программ, процедур, функций и т.п. в виде последовательности букв латинского алфавита и цифр, начинающейся обязательно с буквы;
<служебные слова>: := AND ½ ARRAY ½ BEGIN ½ CASE ½ CONS ½ DIV ½ DOWNTO ½ DO ½ ELSЕ ½ END ½ FILE ½ FOR ½ FUNCTION ½ GOTO ½ IF ½ IN ½ LABEL ½ MOD ½ NIL ½ NOT ½ OF ½ OR ½ PACKED ½ PROCEDURE ½ PROGRAM ½ RECORD ½ REPEAT ½ SET½ THEN ½ TO ½ TYPE ½ UNTIL ½ VAR ½ WHILE ½ WITH ;
<специальные символы>: := + ½ - ½ * ½ / ½ = ½ < ½ > ½ <= ½ >= ½ [ ½ ] ½ (½) ½ _ ½:= ½ " ½ " ½ . ½ , ½: ½ ; ½ ¹ ½# ½$ ;
десятичные числа без знака.
В выражениях и предложениях формального языка, cодержащих лексемы и синтаксические переменные, лексемы всегда заключены в кавычки. Например, "BEGIN", "NOT", AND" и др.
Для обозначения синтаксических переменных введем прописные буквы латинского алфавита. Знаки этого множества называют нетерминальными. Обозначим множество нетерминальных символов знаком V N .
Множество V N - счетно и конечно.
Элементарными синтаксическими переменными для языка программирования являются:
<блок > :: = <блок-операторов>½<блок-процедуры>½<блок-функции>½...;
<заголовок > ::= <заголовок-программы>½<заголовок-процедуры>½
<заголовок-функции>½...;
<идентификатор > ::= <идентификатор-программы>½<идентификатор-
переменной>½...;
<оператор > ::= <оператор-присваивания>½<оператор-ЕСЛИ>...;
<операция > ::= <операция-сложения>½<операция-умножения>
½<операция-отношения>½...;
и другие синтаксические переменные.
В языке Паскаль всего около 240 синтаксических переменных.
В выражениях и предложениях формального языка, содержащих синтаксические переменные, их заключают в угловые скобки. Например, "PROGRAM" <идентификатор-программы> ";" "BEGIN" <блок-операторов> "END" и др.
Объединение символов двух множеств V T и V N представляет множество символов формального языка, т.е.
V = V T ÈV N . (2)
Цепочки символов формального языка могут содержать различное количество терминальных и/или нетерминальных символов. Поэтому множество правильных цепочек может быть записано так:
Если каждый элемент множества V* обозначить строчной буквой греческого алфавита, то множество V* можно описать перечислением его элементов:
V* = { a ; b ; g ;... } (4)
Например,
a:= "PROGRAM"<идентификатор-программы>";"<блок>".";
b:= "CONST" <определение-константы> "; " ;
g:= "(" <идентификатор> { " , " <идентификатор> } ") " ;
где знак ":=" означает: "...присвоить значение...". Цепочка a ÎV* содержит пять символов множества V, цепочка b ÎV* - три символа и цепочка g Î V* - не менее трех символов, т.к. в языках программирования знак "{ .. }" означает многократное повторение выражения, заключенного в фигурные скобки, включая нуль раз.
Конструкция программы на любом языке программирования состоит, как правило, из двух частей: заголовка - <заголовок-программы> и тела программы - <блок>. В заголовке программы, начинающемся служебным словом "PROGRAM", ей присваивается имя (идентификатор), вслед за которым в круглых скобках задается перечень идентификаторов тех файлов, через которые программа взаимодействует с внешним миром. В теле программы должны следовать в определенном порядке разделы меток, констант, типов, переменных, процедур, функций и операторов. Так как разделы, предшествующие разделу операторов, носят описательный характер, то каждый из них может быть пустой цепочкой, а раздел операторов является основным и должен присутствовать в любой программе. Поэтому в последующих объяснениях <блок> содержит только описание операторов, т.е. исполняет функции <блока-операторов>.
Синтаксические правила формальной грамматики можно рассматривать как элементарные операторы подстановки, которые, будучи примененными в определенной последовательности к исходной цепочке терминальных и/или нетерминальных символов, порождают правильные цепочки этих же символов. Поэтому эти правила часто называют правилами подстановки или продукциями.
Продукцию или правило подстановки записывают так:
где a - левая часть правила,
b - правая часть правила.
Если правил несколько,то их необходимо индексировать:
p i: a i::= b i , где i = 1;2;3;... (6)
Левая часть правила не может быть пустой цепочкой и всегда содержит один или несколько нетерминальных символов, т.е.
a ÎV* \ e, где e - пустая цепочка. (7)
Правая часть правила может содержать пустые цепочки и не содержать нетерминальных символов, т.е.
b ÎV * или b ÎV*\ V N . (8)
Пример 3 . Пусть даны несколько правил языка программирования Паскаль:
<программа> ::= <заголовок-программы> " ; "<блок>" . ";
<заголовок-программы> ::= "PROGRAM"<идентификатор-программы>;
<блок> ::= <раздел-операторов> | ...;
<раздел-операторов> ::= "BEGIN" <оператор> " END" ;
<оператор> ::= <оператор-присваивания> |...;
<оператор-присваивания> ::= <переменная> " := " <выражение>;
<выражение> ::= <терм> <операция-сложения> <терм> ;
<терм> ::= <множитель> <операция-умножения> <множитель>;
<множитель> ::= <переменная> ;
<переменная> ::= <идентификатор-переменной> ;
<операция-сложения> ::= " + " | " - " | "OR";
<операция-умножения> ::= " x " | " / " | "DIV" | "MOD" |"AND".
Синтаксической переменной <идентификатор-программы> присвоим какое-либо значение (например, "ALGEBRA"), т.е.
<идентификатор-программы>::= "ALGEBRA".
Cинтаксической переменной <идентификатор-переменной> также присвоим какое-либо значение, начинающееся с буквы (например," i "), т.е.
<идентификатор-переменной> ::= " i ".
Последовательность использования правил подстановки в процессе формирования цепочки терминальных и/или нетерминальных символов называют выводом. Поэтому эти же правила часто называют правилами вывода. Для указания процесса вывода используют знак "=>".
Выводы бывают левосторонние и правосторонние. При левостороннем выводе продукцию применяют к самому левому нетерминальному символу цепочки, а при правостороннем - к самому правому.
Пример 4 . а) Для начального символа <программа> (пример 3) исполнить левосторонний вывод:
<программа> => <заголовок-программы> ";" <блок> "." => "PROGRAM" <идентификатор-программы> ";" <блок> "." => "PROGRAM" "ALGEBRA" ";" <блок> "." => "PROGRAM" "ALGEBRA" ";" <раздел-операторов> "." => <оператор> "END" "." => "PROGRAM" "ALGEBRA" ";" "BEGIN" <оператор-присваивания> "END" "." => ."PROGRAM" "ALGEBRA" ";" "BEGIN" <переменная> ":= " <выражение> "END" "." => "PROGRAM" "ALGEBRA" ";" "BEGIN" <идентификатор-переменной> ":=" <выражение> "END" "." => "PROGRAM" "ALGEBRA" ";" "BEGIN" " i " ":=" <выражение> "END" "." => ..
b) Для начального символа <программа> (пример 3) исполнить правосторонний вывод:
<программа> => <заголовок-программы> ";" <блок> "." => <заголовок-программы> ";" <раздел-операторов> "." => <заголовок-программы> ";" "BEGIN" <оператор> "END" "." => <заголовок-программы> ";" "BEGIN" <оператор-присваивания> "END" "." => <заголовок-программы> ";" "BEGIN" <переменная> ":=" <выражение> "END" "." => ...
Cинтаксической переменной <выражение> может быть любое арифметическое, алгебраическое или логическое выражение. Так как содержание этого выражения не определено, то оба вывода остановились на этой синтаксической переменной. Остальные члены предложения <программа> представлены элементарными лексическими единицами текста программы.,
Пример 5 . Для cинтаксической переменной <выражение> (пример 3) выполнить левосторонний вывод:
<выражение> => <терм><операция-сложения><терм>=> <множитель> <операция-умножения><множитель><операция-сложения><терм> => <переменная><операция-умножения><множитель><операция-сложения> <терм>=> <идентификатор-переменной><операция-умножения> <множитель> <операция-сложения><терм> => "i" <операция-умножения> <множитель><операция-сложения><терм> => "i" "x" <множитель><операция-сложения><терм> => "i" "x" <переменная><операция-сложения><терм> => "i" "x" <идентификатор-переменной><операция-сложения><терм> => "i" "x" "i" <операция-сложения><терм> => "i" "x" "i" "+" <терм> => "i" "x" "i" "+" <множитель><операция-умножения><множитель> => "i" "x" "i" "+" <переменная> <операция-умножения><множитель> => "i" "x" "i" "+" <идентификатор-переменной><операция-умножения> <множитель> => "i" "x" "i" "+" "i" <операция-умножения> <множитель> => "i" "x" "i" "+" "i" "x" <множитель> "i" "x" "i" "+" "i" "x" <переменная> => "i" "x" "i" "+" "i" "x"<идентификатор-переменной> => "i" "x" "i" "+" "i" "x" "I".
Имя начальной синтаксической переменной языка, для которой дано множество правил вывода называют начальным символом и обозначают буквой J. Роль начального символа может исполнять любая синтаксическая переменная. Для текста программы начальной синтаксической переменной является <программа>. Для части текста программы - выражения - начальной синтаксической переменной является <выражение>.
Итак, модель формальной грамматики может быть описана совокупностью четырех основных компонент:
G = á V T ; V N ;J ; P ñ , (9)
где V T = { a;b;c;... } - терминальные символы;
V N = { A;B;C;...} - нетерминальные символы;
JÎ Vn - начальный символ;
P = { p i |i = 1; 2; 3; ... } - синтаксические правила.
Множество правильных цепочек терминальных символов представляет выражения и предложения формального языка данной формальной грамматики L(G) :
L (G) = { a , b , g ,...½ a , b , g Î V *\ VN }. (10)
Текст программы, ограниченный разделителем ".", называют предложением, а часть текста, ограниченную разделителем ";" , - выражением.
Если для начального символа дана цепочка терминальных и/или нетерминальных символов, то формальная грамматика позволяет установить, является ли эта цепочка правильной, и, в случае положительного ответа, выяснить структуру этой цепочки. Такая грамматика называется распознающей. Например, синтаксический анализатор компилятора проверяет текст исходной программы и, в случае положительного ответа, транслирует его на язык вычислительной машины. Для такого анализатора должны быть разработаны правила разбора текста программы.
Если для начального символа не дана цепочка терминальных и/или нетерминальных символов или дана ее часть, то формальная грамматика оказывает помощь в построении синтаксически правильной цепочки терминальных символов с указанием ее состава и структуры. Такая грамматика называется порождающей.
1. Самостоятельные части речи:
- существительные (см. морфологические нормы сущ.);
- глаголы:
- причастия;
- деепричастия;
- прилагательные;
- числительные;
- местоимения;
- наречия;
2. Служебные части речи:
- предлоги;
- союзы;
- частицы;
3. Междометия.
Ни в одну из классификаций (по морфологической системе) русского языка не попадают:
- слова да и нет, в случае, если они выступают в роли самостоятельного предложения.
- вводные слова: итак, кстати, итого, в качестве отдельного предложения, а так же ряд других слов.
Морфологический разбор существительного
- начальная форма в именительном падеже, единственном числе (за исключением существительных, употребляемых только во множественном числе: ножницы и т.п.);
- собственное или нарицательное;
- одушевленное или неодушевленное;
- род (м,ж, ср.);
- число (ед., мн.);
- склонение;
- падеж;
- синтаксическая роль в предложении.
План морфологического разбора существительного
"Малыш пьет молоко."
Малыш (отвечает на вопрос кто?) – имя существительное;
- начальная форма – малыш;
- постоянные морфологические признаки: одушевленное, нарицательное, конкретное, мужского рода, I -го склонения;
- непостоянные морфологические признаки: именительный падеж, единственное число;
- при синтаксическом разборе предложения выполняет роль подлежащего.
Морфологический разбор слова «молоко» (отвечает на вопрос кого? Что?).
- начальная форма – молоко;
- постоянная морфологическая характеристика слова: среднего рода, неодушевленное, вещественное, нарицательное, II -е склонение;
- изменяемые признаки морфологические: винительный падеж, единственное число;
- в предложении прямое дополнение.
Приводим ещё один образец, как сделать морфологический разбор существительного, на основе литературного источника:
"Две дамы подбежали к Лужину и помогли ему встать. Он ладонью стал сбивать пыль с пальто. (пример из: «Защита Лужина», Владимир Набоков)."
Дамы (кто?) - имя существительное;
- начальная форма - дама;
- постоянные морфологические признаки: нарицательное, одушевленное, конкретное, женского рода, I склонения;
- непостоянная морфологическая характеристика существительного: единственное число, родительный падеж;
- синтаксическая роль: часть подлежащего.
Лужину (кому?) - имя существительное;
- начальная форма - Лужин;
- верная морфологическая характеристика слова: имя собственное, одушевленное, конкретное, мужского рода, смешанного склонения;
- непостоянные морфологические признаки существительного: единственное число, дательного падежа;
Ладонью (чем?) - имя существительное;
- начальная форма - ладонь;
- постоянные морфологические признаки: женского рода, неодушевлённое, нарицательное, конкретное, I склонения;
- непостоянные морфо. признаки: единственного числа, творительного падежа;
- синтаксическая роль в контексте: дополнение.
Пыль (что?) - имя существительное;
- начальная форма - пыль;
- основные морфологические признаки: нарицательное, вещественное, женского рода, единственного числа, одушевленное не охарактеризовано, III склонения (существительное с нулевым окончанием);
- непостоянная морфологическая характеристика слова: винительный падеж;
- синтаксическая роль: дополнение.
(с) Пальто (С чего?) - существительное;
- начальная форма - пальто;
- постоянная правильная морфологическая характеристика слова: неодушевленное, нарицательное, конкретное, среднего рода, несклоняемое;
- морфологические признаки непостоянные: число по контексту невозможно определить, родительного падежа;
- синтаксическая роль как члена предложения: дополнение.
Морфологический разбор прилагательного
Имя прилагательное - это знаменательная часть речи. Отвечает на вопросы Какой? Какое? Какая? Какие? и характеризует признаки или качества предмета. Таблица морфологических признаков имени прилагательного:
- начальная форма в именительном падеже, единственного числа, мужского рода;
- постоянные морфологические признаки прилагательных:
- разряд, согласно значению:
- - качественное (теплый, молчаливый);
- - относительное (вчерашний, читальный);
- - притяжательное (заячий, мамин);
- степень сравнения (для качественных, у которых этот признак постоянный);
- полная / краткая форма (для качественных, у которых этот признак постоянный);
- непостоянные морфологические признаки прилагательного:
- качественные прилагательные изменяются по степени сравнения (в сравнительных степенях простая форма, в превосходных - сложная): красивый-красивее-самый красивый;
- полная или краткая форма (только качественные прилагательные);
- признак рода (только в единственном числе);
- число (согласуется с существительным);
- падеж (согласуется с существительным);
- синтаксическая роль в предложении: имя прилагательное бывает определением или частью составного именного сказуемого.
План морфологического разбора прилагательного
Пример предложения:
Полная луна взошла над городом.
Полная (какая?) – имя прилагательное;
- начальная форма – полный;
- постоянные морфологические признаки имени прилагательного: качественное, полная форма;
- непостоянная морфологическая характеристика: в положительной (нулевой) степени сравнения, женский род (согласуется с существительным), именительный падеж;
- по синтаксическому анализу - второстепенный член предложения, выполняет роль определения.
Вот еще целый литературный отрывок и морфологический разбор имени прилагательного, на примерах:
Девушка была прекрасна: стройная, тоненькая, глаза голубые, как два изумительных сапфира, так и заглядывали к вам в душу.
Прекрасна (какова?) - имя прилагательное;
- начальная форма - прекрасен (в данном значении);
- постоянные морфологические нормы: качественное, краткое;
- непостоянные признаки: положительная степень сравнения, единственного числа, женского рода;
Стройная (какая?) - имя прилагательное;
- начальная форма - стройный;
- постоянные морфологические признаки: качественное, полное;
- непостоянная морфологическая характеристика слова: полное, положительная степень сравнения, единственное число, женский род, именительный падеж;
- синтаксическая роль в предложении: часть сказуемого.
Тоненькая (какая?) - имя прилагательное;
- начальная форма - тоненький;
- морфологические постоянные признаки: качественное, полное;
- непостоянная морфологическая характеристика прилагательного: положительная степень сравнения, единственное число, женского рода, именительного падежа;
- синтаксическая роль: часть сказуемого.
Голубые (какие?) - имя прилагательное;
- начальная форма - голубой;
- таблица постоянных морфологических признаков имени прилагательного: качественное;
- непостоянные морфологические характеристики: полное, положительная степень сравнения, множественное число, именительного падежа;
- синтаксическая роль: определение.
Изумительных (каких?) - имя прилагательное;
- начальная форма - изумительный;
- постоянные признаки по морфологии: относительное, выразительное;
- непостоянные морфологические признаки: множественное число, родительного падежа;
- синтаксическая роль в предложении: часть обстоятельства.
Морфологические признаки глагола
Согласно морфологии русского языка, глагол - это самостоятельная часть речи. Он может обозначать действие (гулять), свойство (хромать), отношение (равняться), состояние (радоваться), признак (белеться, красоваться) предмета. Глаголы отвечают на вопрос что делать? что сделать? что делает? что делал? или что будет делать? Разным группам глагольных словоформ присущи неоднородные морфологические характеристики и грамматические признаки.
Морфологические формы глаголов:
- начальная форма глагола - инфинитив. Ее так же называют неопределенная или неизменяемая форма глагола. Непостоянные морфологические признаки отсутствуют;
- спрягаемые (личные и безличные) формы;
- неспрягаемые формы: причастные и деепричастные.
Морфологический разбор глагола
- начальная форма - инфинитив;
- постоянные морфологические признаки глагола:
- переходность:
- переходный (употребляется с существительными винительного падежа без предлога);
- непереходный (не употребляется с существительным в винительном падеже без предлога);
- возвратность:
- возвратные (есть -ся, -сь);
- невозвратные (нет -ся, -сь);
- несовершенный (что делать?);
- совершенный (что сделать?);
- спряжение:
- I спряжение (дела-ешь, дела-ет, дела-ем, дела-ете, дела-ют/ут);
- II спряжение (сто-ишь, сто-ит, сто-им, сто-ите, сто-ят/ат);
- разноспрягаемые глаголы (хотеть, бежать);
- непостоянные морфологические признаки глагола:
- наклонение:
- изъявительное: что делал? что сделал? что делает? что сделает?;
- условное: что делал бы? что сделал бы?;
- повелительное: делай!;
- время (в изъявительном наклонении: прошедшее/настоящее/будущее);
- лицо (в настоящем/будущем времени, изъявительного и повелительного наклонения: 1 лицо: я/мы, 2 лицо: ты/вы, 3 лицо: он/они);
- род (в прошедшем времени, единственного числа, изъявительного и условного наклонения);
- число;
- синтаксическая роль в предложении. Инфинитив может быть любым членом предложения:
- сказуемым: Быть сегодня празднику;
- подлежащим:Учиться всегда пригодится;
- дополнением: Все гости просили ее станцевать;
- определением: У него возникло непреодолимое желание поесть;
- обстоятельством: Я вышел пройтись.
Морфологический разбор глагола пример
Чтобы понять схему, проведем письменный разбор морфологии глагола на примере предложения:
Вороне как-то Бог послал кусочек сыру... (басня, И. Крылов)
Послал (что сделал?) - часть речи глагол;
- начальная форма - послать;
- постоянные морфологические признаки: совершенный вид, переходный, 1-е спряжение;
- непостоянная морфологическая характеристика глагола: изъявительное наклонение, прошедшего времени, мужского рода, единственного числа;
Следующий онлайн образец морфологического разбора глагола в предложении:
Какая тишина, прислушайтесь.
Прислушайтесь (что сделайте?) - глагол;
- начальная форма - прислушаться;
- морфологические постоянные признаки: совершенный вид, непереходный, возвратный, 1-го спряжения;
- непостоянная морфологическая характеристика слова: повелительное наклонение, множественное число, 2-е лицо;
- синтаксическая роль в предложении: сказуемое.
План морфологического разбора глагола онлайн бесплатно, на основе примера из целого абзаца:
Его нужно предостеречь.
Не надо, пусть знает в другой раз, как нарушать правила.
Что за правила?
Подождите, потом скажу. Вошел! («Золотой телёнок», И. Ильф)
Предостеречь (что сделать?) - глагол;
- начальная форма - предостеречь;
- морфологические признаки глагола постоянные: совершенный вид, переходный, невозвратный, 1-го спряжения;
- непостоянная морфология части речи: инфинитив;
- синтаксическая функция в предложении: составная часть сказуемого.
Пусть знает (что делает?) - часть речи глагол;
- начальная форма - знать;
- непостоянная морфология глагола: повелительное наклонение, единственного числа, 3-е лицо;
- синтаксическая роль в предложении: сказуемое.
Нарушать (что делать?) - слово глагол;
- начальная форма - нарушать;
- постоянные морфологические признаки: несовершенный вид, невозвратный, переходный, 1-го спряжения;
- непостоянные признаки глагола: инфинитив (начальная форма);
- синтаксическая роль в контексте: часть сказуемого.
Подождите (что сделайте?) - часть речи глагол;
- начальная форма - подождать;
- постоянные морфологические признаки: совершенный вид, невозвратный, переходный, 1-го спряжения;
- непостоянная морфологическая характеристика глагола: повелительное наклонение, множественного числа, 2-го лица;
- синтаксическая роль в предложении: сказуемое.
Вошел (что сделал?) - глагол;
- начальная форма - войти;
- постоянные морфологические признаки: совершенный вид, невозвратный, непереходный, 1-го спряжения;
- непостоянная морфологическая характеристика глагола: прошедшее время, изъявительное наклонение, единственного числа, мужского рода;
- синтаксическая роль в предложении: сказуемое.
Л А Б О Р А Т О Р Н А Я Р А Б О Т А №1
Cоздание формальной грамматики и построение
Цель работы – изучение структуры языка программирования и запись ее в формальном виде; построение выводов на основе полученной грамматики для проверки ее правильности.
ОСНОВНЫЕ СВЕДЕНИЯ
Создание грамматики языка
Языки программирования, используемые в настоящее время для решения задач на ЭВМ, значительно отличаются друг от друга своей структурой и средствами описания алгоритмов. Различны также и методы отладки и выполнения программ, написанных на этих языках.
Каковы же основные принципы проектирования и разработки новых языков программирования? Каким требованиям должен удовлетворять язык, рассчитанный на широкое использование при решении задач на ЭВМ? В первую очередь, язык должен быть удобен для программиста. В частности, он должен быть легок в изучении, а также иметь средства, позволяющие с минимальными затратами времени подготовить задачи к решению на ЭВМ. С другой стороны, должны учитываться характеристики работы ЭВМ с программой: память, необходимая для обработки программы, количество машинного времени для решения задачи и пр. К сожалению, эти требования являются в известной степени трудно совместимыми. То, что «удобно» для ЭВМ, оказывается не совсем удобным для программиста и наоборот. Но, т.к. любая задача содержит, как правило и те, и другие требования к используемому языку, то при его создании необходимо учитывать обе стороны работы с ним.
Подводя итог вышесказанному, можно сделать следующий вывод. Для создания языка программирования необходим такой математический и теоретический аппарат, который бы формально мог описать структуру любого языка, с одной стороны, а с другой – по возможности бы учел машинные требования к создаваемому языку.
Основным определением такого аппарата является определение формального языка. Всякий язык программирования можно определить как множество предложений – некоторое множество цепочек или конечных последовательностей элементарных единиц из некоторого непустого конечного множества символов, называемого словарем или алфавитом. При таком рассмотрении языка программирования задается только множество символов, которые можно использовать для записи программы, а также класс допустимых или синтаксически правильных программ и при этом не затрагивается вопрос задания смысла каждой правильной программы. Чтобы отличать употребление слова «язык» в значении точно определенного множества цепочек от употребления этого слова в повседневной речи, множество цепочек иногда называют формальным языком .
Обычный подход, удовлетворяющий указанному выше требованию задания языка, состоит в том, что предложения языка образуются по определенным правилам, в совокупности составляющим то, что называют грамматикой языка. Эти грамматические правила приписывают предложениям языка некоторую синтаксическую структуру, которая может использоваться при задании и определении смысла предложений.
Синтаксис – внешнее представление предложений языка.
Семантика – смысловое содержание предложений языка.
Набор правил, определяющих синтаксис языка, образует грамматику языка.
Формальная грамматика – абстрактное обобщение грамматики естественных языков – рассматривает строки (цепочки) символов.
Формальная грамматика есть четверка
G
= { V
, V
 ,
P
, S
},
,
P
, S
},
где V- алфавит терминальных символов, т.е. символов, которые могут входить в левые части правил (соответствует набору слов и знаков языка);
V -алфавит
нетерминальных символов (соответствует
набору обобщающих понятий языка);
-алфавит
нетерминальных символов (соответствует
набору обобщающих понятий языка);
Р - набор порождающих правил вида
где и - цепочки терминальных и нетерминальных символов;
S - начальный символ грамматики (соответствует начальному понятию).
Грамматика G для любой цепочки задает множество выводимых из нее цепочек, определяя их рекурсивно следующим образом: если содержится в Р, то цепочка r = непосредственно выводима из (обозначается r), если выводима из и r , то r нетривиально выводима из ( + r) ; если + r или =r, то r выводима из (=*r). Последовательность применения правил 1 2 ... r называется выводом цепочки , если 1 = S, r = .
Цепочка, выводимая из S, называется сентенциальной формой . Сентенциальная форма не содержащая нетерминальных символов, называется предложением . Множество предложений образует язык , порожденный грамматикой G (L(G)).
Формы Бэкуса-Науэ р а (БНФ)
Широко используемой формой записи правил грамматик являются формы Бэкуса-Науэра (БНФ).
Нормальные формы Бэкуса – язык, специально разработанный для описания синтаксиса других языков программирования. Основное назначение форм Бэкуса заключается в представлении в сжатом и компактном виде строго формальных и однозначных правил написания основных конструкций описываемого языка программирования.
Т.к. любое предложение языка можно рассматривать как цепочку основных символов этого языка, то в результате использования в определенном порядке форм Бэкуса, описывающих синтаксис языка, возможно построение любой правильной программы на этом языке.
Характерной особенностью языков программирования, так же как и естественных языков, является то, что в сложные синтаксические конструкции в качестве составных частей входят другие конструкции. Так, программа на языке TurboPascal является обычно блоком, который в свою очередь может включать в себя один или несколько внутренних блоков. Блок также является сложной конструкцией, включающей в себя описания, операторы; последние тоже имеют составные части и т.д. Таким образом, для того, чтобы написать программу, необходимо знать правила написания блоков и других конструкций, входящих в программу в качестве составных частей. Вторым классом объектов, используемых в формах Бэкуса, как раз и являются имена конструкций описываемого языка, или так называемые металингвистические переменные. Значение металингвистических переменных – это цепочки основных символов описываемого языка.
Каждая металингвистическая формула описывает правила построения некоторой конструкции языка и состоит из двух частей. В левой части находится металингвистическая переменная, обозначающая соответствующую конструкцию (нетерминальный (НТ) символ). Далее следует так называемая металингвистическая связка:: =, проставляемая вместо символа и имеющая смысл глагола «быть». Она соединяет левую и правую части формулы. В правой части формулы указывается один или несколько вариантов построения конструкции, определенной в левой части. Каждый вариант представляет собой цепочку, состоящующую из металингвистических переменных и основных символов (терминальных(Т)). Для того, чтобы построить конструкцию, определяемую формулой, нужно выбрать некоторый вариант построения из правой части формулы и, используя соответствующие формулы вместо каждой металингвистической переменной некоторые цепочки основных символов. Варианты правой части формулы разделяются металингвистической связкой |, имеющей значение «или».
Наконец, необходимо отметить, что металингвистические переменная может обозначаться словами или некоторыми именами, заключенными в угловые скобки. Имя металингвистической переменной присваивается программистом и поясняет смысл описываемой конструкции, например: арифметическое выражение.
Пример формальной грамматики, записанной в формах Бэкуса-Науэра.
Опишем грамматику образования целых чисел. Каждое число может быть одноразрядным, т.е. состоять из одной цифры - 5, а может быть многоразрядным - 55, т.е. состоять более чем из одной цифры. Для того, чтобы образовать многоразрядное число, необходимо зациклить конструкцию на самою себя.
Грамматика G1 записи числа содержит следующие 13 правил:
(1) число::= чс
(2) чс::= чс цифра
(3) чс::= цифра
(4) цифра::= 0
(5) цифра::= 1
(6) цифра::= 2
(7) цифра::= 3
(8) цифра::= 4
(9) цифра::= 5
(10) цифра::= 6
(11) цифра::= 7
(12) цифра::= 8
(13) цифра::= 9
G1 = {{0,1,2,3,4,5,6,7,8,9}, {цифра, число, чс}, Р, число },
Где первое указанное множество – алфавит терминальных символов;
второе указанное множество – алфавит нетерминальных символов;
Р - 13 правил, указанных выше;
число - начальный символ грамматики.
Поскольку в формах Бэкуса-Науэра вариант “или” записывается знаком «|», то грамматику необходимо записать так:
число::= чс
чс::= чс цифра | цифра
цифра::= 0|1|2|3|4|5|6|7|8|9
Классификация
Хомского

Грамматики можно классифицировать по виду их правил.
Существует четыре вида грамматик:
грамматика с фразовой структурой (на ней построены естественные языки);
контекстно-зависимые грамматики (вид каждой сентенциальной формы зависит от того, в каком контексте находится символ, заменяемый по определенному правилу цепочкой символов);
контекстно-свободные (КС) грамматики, где каждое правило имеет вид:
где
V ,
а
- цепочка в алфавите V
V
,
а
- цепочка в алфавите V
V ;
;
автоматные грамматики, где каждое правило имеет вид:
х В или
х, где
х
V,
{,B}
V .
.
Язык L называется автоматным, контекстно-свободным, контекстно-зависимым или с фразовой структурой, если существует определяющая его грамматика G соответствующего типа, для которой L = L(G).
Аннотация: В данном разделе рассматриваются основы дисциплины: "формальная грамматика". Эта дисциплина рассматривает любые операции с символами, а ее выводы широко используются при анализе формальных и "человеческих" языков, а также в искусственном интеллекте. Эта лекция является самой важной и, одновременно, самой сложной для понимания лекцией курса. В связи с этим автор преподносит читателю только ее выводы, опуская математические доказательства. Для лучшего понимания материала может потребоваться обращение к материалам предыдущих и последующих лекций.
10.1. Алфавит
Изучение любого языка человек начинает с азбуки. В формальной грамматике язык определяется вне зависимости от его смысла. Более того, один и тот же язык может формироваться несколькими грамматиками! Это как в школе - не так важен результат (который можно прочитать в конце учебника), как его получение - зафиксированное в тетради решение задачи. Поэтому подойдем к определению алфавита также формально.
О п р е д е л е н и е . Алфавит - это непустое конечное множество элементов.
В "классическом" языке алфавит - это набор литер. В фонетике - набор издаваемых человеком звуков речи. В музыке - это набор нот, и т.д.
С помощью алфавита часто возможно описать бесконечное множество слов. Совокупность всех слов, которую можно создать при помощи грамматики (иначе говоря, порождаемые грамматикой ), называется языком. В отличие от алфавита язык может быть бесконечным.
Всякая конечная последовательность символов алфавита называется словом, или, более профессионально, цепочкой. Цепочками, состоящими из символов {a, b, c}, будут следующие последовательности: a, b, c, aa, ab, bc, ac , bb, abba и другие. Также допускается существование пустой цепочки Л - полное отсутствие символов. Важен также порядок следования символов в цепочке. Так, цепочки ab и ba - разные цепочки. Далее заглавные латинские буквы будут использованы как переменные и символы, а строчные латинские буквы будут обозначать цепочки. Например:
X = SVT Листинг 10.1.
цепочка, состоящая из символов S , V и T , и именно в этом порядке.
О п р е д е л е н и е . Длиной цепочки называется число символов в этой цепочке. Она обозначается как |x| . Например: |Л| = 0, |A| = 1, |BA| = 2, |ABBA| = 4 .
Если x и y являются цепочками, то их конкатенацией будет цепочка xy . От перестановки цепочек при конкатенации результат меняется (как и в теории групп). Если z = xy - цепочка, то x - голова, а y - хвост цепочки. Если нам безразлична голова цепочки, мы будем обозначать:
Z = … x Листинг 10.2.
а если нам безразличен хвост, мы будем писать:
Z = x … Листинг 10.3.
О п р е де л е н и е . Произведение двух множеств цепочек определяется как конкатенация всех цепочек, входящих в эти множества . Например, если множество A = {a, b}, а B = {c,d} , то:
AB = {ac, ad, bc, bd} Листинг 10.4.
В произведении множеств, как и при конкатенации, порядок множителей существенен.
И при конкатенации цепочек, и при перемножении множеств цепочек истинным остается ассоциативный закон, записывающийся как:
Z = (ab)c = a(bc) = abc Листинг 10.5.
D = (AB)C = A(BC) = ABC Листинг 10.6.
И, наконец, определим степень цепочки. Если x - непустая цепочка, то x 0 = {Л}, x 1 = x, x 2 = xx, x n = x(x) (n-1) . То же самое обстоит и со степенью множеств.
10.2. Терминальные и нетерминальные символы
Понятие терминальных и нетерминальных символов тесно связано с понятием правила подстановки (или продукции). Дадим его определение .
О п р е д е л е н и е . Продукцией, или правилом подстановки, называется упорядоченная пара (U, x ), записываемая как:
U::= x Листинг 10.7.
где U - символ, а x - непустая конечная цепочка символов .
Символы, встречающиеся только в правой части, называются терминальными символами . Символы, встречающиеся и в левой, и в правой части правил, называются нетерминальными символами, или синтаксическими единицами языка. Множество нетерминальных символов обозначается как VN, а терминальных символов - VT.
Примечание . Данное определение терминальных и нетерминальных символов истинно для КС- грамматик и A- грамматик (см. раздел 10.4.3).
О п р е д е л е н и е . Грамматикой G[Z] называют конечное, непустое множество правил, содержащее нетерминальный символ Z хотя бы один раз на множестве правил. Символ Z называют начальным символом. Далее мы все нетерминальные символы будем обозначать как <символ>.
[Пример 01]
Грамматика : "число"
<число> ::= <чс> <чс> ::= <цифра> <чс> ::= <чс><цифра> <цифра> ::= 0 <цифра> ::= 1 <цифра> ::= 2 <цифра> ::= 3 <цифра> ::= 4 <цифра> ::= 5 <цифра> ::= 6 <цифра> ::= 7 <цифра> ::= 8 <цифра> ::= 9
Дадим еще определение :
О п р е д е л е н и е . Цепочка v непосредственно порождает цепочку w , если:
V = xy, а w = xuy Листинг 10.8.
где ::= u - правило грамматики . Это обозначается как v => w . Мы также говорим, что цепочка w непосредственно выводима из v . При этом цепочки x и y могут быть пустыми.
О п р е д е л е н и е . Говорят, что v порождает w , или w приводится к v , если существует конечная цепочка выводов u0, u1, …, u[n] (n > 0) , такая, что
V = u0 => u1 => u2 => … => u[n] = w Листинг 10.9.
Эта последовательность называется выводом длиной n , и обозначается v =>+ w . И, наконец, пишут:
V =>* w, если v => w или v =>+ w Листинг 10.10.
10.3. Фразы
О п р е д е л е н и е
. Пусть G[Z]
- грамматика
, x
- цепочка. Тогда x
называют сентенциальной формой, если
О п р е д е л е н и е . Пусть G[Z] - грамматика . И пусть w = xuy - сентенциальная форма. Тогда u называется фразой сентенциальной формы w для нетерминального символа , если:
Z =>* xy и =>+ u Листинг 10.11.
Z =>* xy и => u Листинг 10.12.
то цепочка u называется простой фразой.
Следует быть осторожным с термином "фраза". Тот факт, что =>+ u (цепочка u выводима из ) вовсе не означает, что u является фразой сентенциальной формы xy; необходима также выводимость цепочки xy из начального символа грамматики Z .
В качестве иллюстрации фразы рассмотрим [Пример 01] сентенциальную форму <чс>1 . Значит ли это, что символ <чс> является фразой, если существует правило: <число> ::= <чс> ? Конечно же, нет, поскольку невозможен вывод цепочки: <число><1> - из начального символа: <число> . Какие же фразы сентенциальной формы <чс>1 ? Рассмотрим вывод :
<число> => <чс> => <чс><цифра> => <чс><1> Листинг 10.13.
Таким образом,
<число> =>* <чс> и <чс> =>+ <чс>1 Листинг 10.14.
- Tutorial
Мотивация
Время от времени на Хабре публикуются посты и переводные статьи, посвященные тем или иным аспектам теории формальных языков. Среди таких публикаций (не хочется указывать конкретные работы, чтобы не обижать их авторов), особенно среди тех, которые посвящены описанию различных программных инструментов обработки языков, часто встречаются неточности и путаница. Автор склонен считать, что одной из основных причин, приведших к такому прискорбному положению вещей, является недостаточный уровень понимания идей, лежащих в основании теории формальных языков.Этот текст задуман как популярное введение в теорию формальных языков и грамматик. Эта теория считается (и, надо сказать, справедливо) довольно сложной и запутанной. На лекциях студенты обычно скучают и экзамены тем более не вызывают энтузиазма. Поэтому и в науке не так много исследователей в этой тематике. Достаточно сказать, что за все время, с зарождения теории формальных грамматик в середине 50-х годов прошлого века и до наших дней, по этому научному направлению было выпущено всего две докторских диссертации. Одна из них была написана в конце 60-х годов Алексеем Владимировичем Гладким, вторая уже на пороге нового тысячелетия - Мати Пентусом.
Далее в наиболее доступной форме описаны два основных понятия теории формальных языков: формальный язык и формальная грамматика. Если тест будет интересен аудитории, то автор дает торжественное обещание разродиться еще парой подобных опусов.
Формальные языки
Коротко говоря, формальный язык - это математическая модель реального языка. Под реальным языком здесь понимается некий способ коммуникации (общения) субъектов друг с другом. Для общения субъекты используют конечный набор знаков (символов), которые проговариваются (выписываются) в строгом временном порядке, т.е. образуют линейные последовательности. Такие последовательности обычно называют словами или предложениями. Таким образом, здесь рассматривается только т.н. коммуникативная функция языка, которая изучается с использованием математических методов. Другие функции языка здесь не изучаются и, потому, не рассматриваются.Чтобы лучше разобраться в том, как именно изучаются формальные языки, необходимо сначала понять, в чем заключаются особенности математических методов изучения. Согласно Колмогорову и др. (Александров А.Д., Колмогоров А.Н., Лаврентьев М.А. Математика. Ее содержание, методы и значение. Том 1. М.: Издательство Академии Наук СССР, 1956.), математический метод, к чему бы он ни применялся, всегда следует двум основным принципам:
- Обобщение (абстрагирование). Объекты изучения в математике - это специальные сущности, которые существуют только в математике и предназначены для изучения математиками. Математические объекты образуются путем обобщения реальных объектов. Изучая какой-нибудь объект, математик замечает только некоторые его свойства, а от остальных отвлекается. Так, абстрактный математический объект «число» может в реальности обозначать количество гусей в пруду или количество молекул в капле воды; главное, чтобы о гусях и о молекулах воды можно было
говорить как о совокупностях. Из такой «идеализации» реальных объектов следует одно важное свойство: математика часто оперирует бесконечными совокупностями, тогда как в реальности таких совокупностей не существует. - Строгость рассуждений. В науке принято для выяснения истинности того или иного рассуждения сверять их результаты с тем, что существует в действительности, т.е. проводить эксперименты. В математике этот критерий проверки рассуждения на истинность не работает. Поэтому выводы не проверяются экспериментальным путем, но принято доказывать их справедливость строгими, подчиняющимися определенным правилам, рассуждениями. Эти рассуждения называются доказательствами и доказательства служат единственным способом обоснования верности того или иного утверждения.
В качестве известного примера такой математической абстракции можно привести модель, известную под неблагозвучным для русского уха названием «мешок слов». В этой модели исследуются тексты естественного языка (т.е. одного из тех языков, которые люди используют в процессе повседневного общения между собой). Основной объект модели мешка слов - это слово, снабженное единственным атрибутом, частотой встречаемости этого слова в исходном тексте. В модели не учитывается, как слова располагаются рядом друг с другом, только сколько раз каждое слово встречается в тексте. Мешок слов используется в машинном обучении на основе текстов в качестве одного из основных объектов изучения.
Но в теории формальных языков представляется важным изучить законы расположения слов рядом друг с другом, т.е. синтаксические свойства текстов. Для этого модель мешка слов выглядит бедной. Поэтому формальный язык задается как множество последовательностей, составленных из элементов конечного алфавита. Определим это более строго.
Алфавит представляет собой конечное непустое множество элементов. Эти элементы будем называть символам. Для обозначения алфавита обычно будем использовать латинское V, а для обозначения символов алфавита - начальные строчные буквы латинского алфавита. Например, выражение V = {a,b} обозначает алфавит из двух символов a и b.
Цепочка представляет собой конечную последовательность символов. Например, abc - цепочка из трех символов. Часто при обозначении цепочек в символах используют индексы. Сами цепочки обозначают строчными символами конца греческого алфавита. Например, omega = a1...an - цепочка из n символов. Цепочка может быть пустой, т.е. не содержать ни одного символа. Такие цепочки будем обозначать греческой буквой эпсилон.
Наконец, формальный язык L над алфавитом V - это произвольное множеств цепочек, составленных из символов алфавита V. Произвольность здесь означает тот факт, что язык может быть пустым, т.е. не иметь ни одной цепочки, так и бесконечным, т.е. составленным из бесконечного числа цепочек. Последний факт часто вызывает недоумение: разве имеются реальные языки, которые содержат бесконечное число цепочек? Вообще говоря, в природе все конечно. Но мы здесь используем бесконечность как возможность образования цепочек неограниченной длины. Например, язык, который состоит из возможных имен переменных языка программирования C++, является бесконечным. Ведь имена переменных в C++ не ограничены по длине, поэтому потенциально таких имен может быть бесконечно много. В реальности, конечно, длинные имена переменных не имеют для нас особого смысла т.к. к концу чтения такого имени уже забываешь его начало. Но в качестве потенциальной возможности задавать неограниченные по длине переменные, это свойство выглядит полезным.
Итак, формальные языки - это просто множества цепочек, составленных из символов некоторого конечного алфавита. Но возникает вопрос: как можно задать формальный язык? Если язык конечен, то можно просто выписать все его цепочки одну за другой (конечно, можно задуматься, имеет ли смысл выписывать цепочки языка, имеющего хотя бы десять тысяч элементов и, вообще, есть ли смысл в таком выписывании?). Что делать, если язык бесконечен, как его задавать? В этот момент на сцену выходят грамматики.
Формальные грамматики
Способ задания языка называет грамматикой этого языка. Таким образом, грамматикой мы называем любой способ задания языка. Например, грамматика L = {a^nb^n} (здесь n - натуральное число) задает язык L, состоящий из цепочек вида ab, aabb, aaabbb и т.д. Язык L представляет собой бесконечное множество цепочек, но тем не менее, его грамматика (описание) состоит всего из 10 символов, т.е. конечна.Назначение грамматики - задание языка. Это задание обязательно должно быть конечным, иначе человек не будет в состоянии эту грамматику понять. Но каким образом, конечное задание описывает бесконечные совокупности? Это возможно только в том случае, если строение всех цепочек языка основано на единых принципов, которых конечное число. В примере выше в качестве такого принципа выступает следующий: «каждая цепочка языка начинается с символов a, за которыми идет столько же символов b». Если язык представляет собой бесконечную совокупность случайным образом набранных цепочек, строение которых не подчиняется единым принципам, то очевидно для такого языка нельзя придумать грамматику. И здесь еще вопрос, можно или нет считать такую совокупность языком. В целях математической строгости и единообразия подхода обычно такие совокупности языком считают.
Итак, грамматика языка описывает законы внутреннего строения его цепочек. Такие законы обычно называют синтаксическими закономерностями. таким образом, можно перефразировать определение грамматики, как конечного способа описания синтаксических закономерностей языка. Для практики интересны не просто грамматики, но грамматики, которые могут быть заданы в рамках единого подхода (формализма или парадигмы). Иначе говоря, на основе единого языка (метаязыка) описания грамматик всех формальных языков. Тогда можно придумать алгоритм для компьютера, который будет брать на вход описание грамматики, сделанное на этом метаязыке, и что-то делать с цепочками языка.
Такие парадигмы описания грамматик называют синтаксическими теориями. Формальная грамматика - это математическая модель грамматики, описанная в рамках какой-то синтаксической теории. Таких теорий придумано довольно много. Самый известный метаязык для задания грамматик - это, конечно, порождающие грамматики Хомского. Но имеются и другие формализмы. Один из таких них - окрестностные грамматики, будет описан чуть ниже.
С алгоритмической точки зрения грамматики можно подразделить по способу задания языка. Имеются три основных таких способа (вида грамматик):
- Распознающие грамматики. Такие грамматики представляют собой устройства (алгоритмы), которым на вход подается цепочка языка, а на выходе устройство печатает «Да», если цепочка принадлежит языку, и «Нет» - в противном случае.
- Порождающие грамматики. Этот вид устройств используется для порождения цепочек языков по требованию. Образно говоря, при нажатии кнопки будет сгенерирована некоторая цепочка языка.
- Перечисляющие грамматики. Такие грамматики печатают одну за другой все цепочки языка. Очевидно, что если язык состоит из бесконечного числа цепочек, то процесс перечисления никогда не остановится. Хотя, конечно его можно остановить принудительно в нужный момент времени, например, когда будет напечатана нужная цепочка.
Окрестностные грамматики
В середине 60-х годов советский математик Юлий Анатольевич Шрейдер предложил простой способ описания синтаксиса языков на основе т.н. окрестностных грамматик. Для каждого символа языка задается конечное число его «окрестностей» - цепочек, содержащих данный символ (центр окрестности) где-то внутри. Набор таких окрестностей для каждого символа алфавита языка называется окрестностной грамматикой. Цепочка считается принадлежащей языку, задаваемому окрестностной грамматикой, если каждый символ этой цепочки входит в нее вместе с некоторой своей окрестностью.В качестве примера рассмотрим язык A = {a+a, a+a+a, a+a+a+a,...} . Этот язык представляет собой простейшую модель языка арифметических выражений, где роль чисел играет символ «a», а роль операций - символ "+". Составим для этого языка окрестностную грамматику. Зададим окрестности для символа «a». Символ «a» может встречаться в цепочках языка A в трех синтаксических контекстах: вначале, между двумя символами "+" и в конце. Для обозначения начала и конца цепочки введем псевдосимвол "#". Тогда окрестности символа «a» будут следующими: #a+, +a+, +a# . Обычно для выделения центра окрестности этот символ в цепочке подчеркивается (ведь в цепочке могут быть и другие такие символы, которые не являются центром!), здесь этого делать не будем за неимением простой технической возможности. Символ "+" встречается только между двух символов «a», поэтому для него задается одна окрестность, цепочка a+a .
Рассмотрим цепочку a+a+a и проверим, принадлежит ли она языку. Первый символ «a» цепочки входит в нее вместе с окрестностью #a+ . Второй символ "+" входит в цепочку вместе с окрестностью a+a . Подобное вхождение можно проверить и для остальных символов цепочки, т.е. данная цепочка принадлежит языку, как и следовало ожидать. Но, например, цепочка a+aa языку A не принадлежит, поскольку последний и предпоследний символы «a» не имеют окрестностей, с которыми они входят в эту цепочку.
Не всякий язык может быть описан окрестностной грамматикой. Рассмотрим, например, язык B, цепочки которого начинаются либо с символа «0», либо с символа «1». В последнем случае далее в цепочке могут идти символы «a» и «b». Если же цепочка начинается с нуля, то далее могут идти только символы «a». Нетрудно доказать, что для этого языка нельзя придумать никакой окрестностной грамматики. Легитимность вхождения символа «b» в цепочку обусловлена ее первым символом. Для любой окрестностной грамматики, в которой задается связь между символами «b» и «1» можно будет подобрать достаточно длинную цепочку, чтобы всякая окрестность символа «b» не доставала до начала цепочки. Тогда в начало можно будет подставить символ «0» и цепочка будет принадлежать языку A, что не отвечает нашим интуитивным представлениям о синтаксическом строении цепочек этого языка.
С другой стороны, легко можно построить конечный автомат, который распознает этот язык. Значит, класс языков, которые описываются окрестностными грамматиками, уже класса автоматных языков. Языки, задаваемые окрестностными грамматиками, будем называть шрейдеровскими. Таким образом, в иерархии языков можно выделить класс шрейдеровских языков, который является подклассом автоматных языков.
Можно сказать, что шрейдеровские языки задают одно простое синтаксическое отношение - «быть рядом» или отношение непосредственного предшествования. Отношение дальнего предшествования (которое, очевидно, присутствует в языке B) окрестностной грамматикой задано быть не может. Но, если визуализировать синтаксические отношения в цепочках языка, то для диаграмм отношений, в которые превращаются такие цепочки, можно придумать окрестностную грамматику.